Tuning Elixir GenStage/Flow pipeline processing
There are many use cases for GenStage/Flow.
One of such cases that I recently faced was to get some records from PostgreSQL database, download files associated with these records from Amazon S3, extract text from these files and index this text into ElasticSearch.
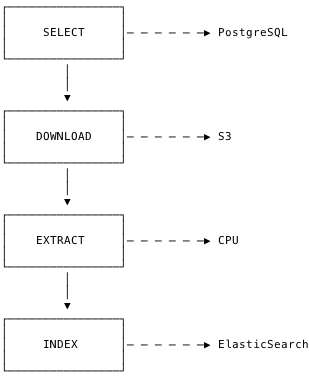
This task can be represented as a pipeline with four steps:
- SELECT record from database
- DOWNLOAD pdf file
- EXTRACT text from that file
- INDEX extracted text
Since I was dealing with hundreds of thousands of records I had to find an efficient way of pipeline processing.
Here is an example how you could implement efficient parallel processing with just few lines of code.
Understanding the problem
The basic question that has to be asked was: “so, what’s the problem?”. Before jumping into conclusions it is crucial to understand the problem we are dealing with.
In our processing pipeline every step has a different characteristic:
- SELECT: We need to execute some SQL query that will return 100.000s records. This is best done using PostgreSQL cursors. With recently added Repo.stream we can do that easily. This step is a single, serial source that will emit a continouous stream of records.
- DOWNLOAD: This step is mostly doing network IO which should be easily parallelized.
- EXTRACT: This one is mostly CPU work - it can also be parallelized on multiple cores.
- INDEX: ElasticSearch indexing is performing best when done in batches, much better than one document at a time.
Such simple analysis gives us a high-level overview with what we need to deal. And it turned out that this is a perfect example to make use of GenStage and especially Flow
Implementation
GenStage separates pipeline stages into three different types:
- Producer - takes no input and emits events - in our case this is the SELECT step
- Producer-Consumer - receives some events and emits some other events - in our case DOWNLOAD and EXTRACT steps
- Consumer - receives events but does not emit any - in our case the INDEX step
You can think of each stage as a simple function:
@spec select :: Stream
def select, do: ...
@spec download(record) :: file
def download(record), do: ...
@spec extract(file) :: text
def extract(file), do: ...
@spec index([text]) :: nothing
def index(texts), do: ...
The full pipeline looks like this:
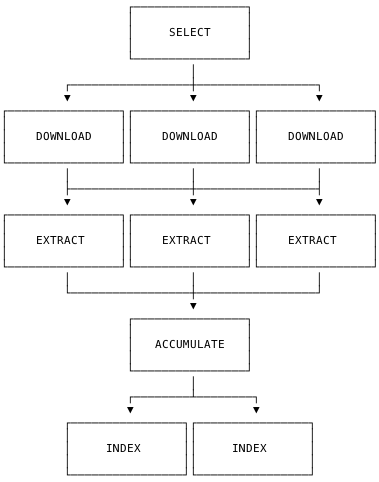
- One SELECT stage
- Some DOWNLOAD stages
- Some EXTRACT stages
- ACCUMULATE stage that is required to prepare batches for next stage
- Some INDEX stages
All we need to run all these stages is these 12 lines of code:
def perform do
# we start with calling select/0 function to get the stream
select
# then we convert it to Flow
|> Flow.from_enumerable(max_demand: 100)
# then distribute that flow of records into 50 processes
|> Flow.partition(max_demand: 100, stages: 50)
# each calling download/1 function for every record received
|> Flow.map(&download/1)
# the result is a flow of files which we again distribute into 50 processes
|> Flow.partition(max_demand: 100, stages: 50)
# each calling extract/1 function for every file received
|> Flow.map(&extract/1)
# since we want do to indexing in batches of 100 we need to accumulate
# the flow of texts into chunks using Window.count/1
|> Flow.partition(window: Flow.Window.count(100), stages: 1)
# the Flow.reduce/2 function takes two arguments:
# - the accumulator init function called at start of every batch
# - the reduce function called for every item in this batch
# What we have here is simply putting incoming items into a list.
|> Flow.reduce(fn -> [] end, fn item, list -> [item | list] end)
# right now our flow events are still single texts, so we need to tell flow
# that we are interested in reducer states from now on
|> Flow.emit(:state)
# finally, we use the same Flow.partition function to start 10 processes
|> Flow.partition(max_demand: 100, stages: 10)
# calling index/1 for every list of 100 texts
|> Flow.map(&index/1)
# and at the end we simply run the flow which will block until
# the whole pipeline is finished
|> Flow.run
end
end
And that’s it?
Unfortunately not, we are not quite there yet.
Tuning
In the example above I have used somehow arbitrary values for max_demand and stages parameters.
While this code works and produces correct results the performance characteristic is far from perfect.
Take a look at the graph below produced on sample data of around 700 records.
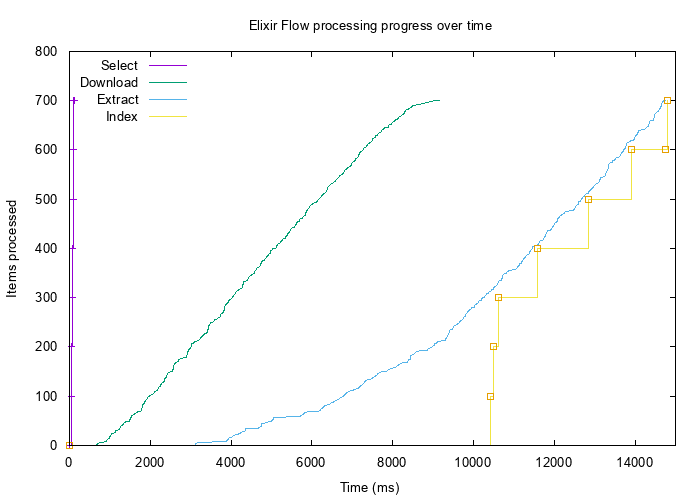
Each line represents the number of items processed by each stage in time. As you can see the SELECT stage immediately fetched all 700 records from database putting it all in memory. The EXTRACT stages hadn’t started processing after around 3 seconds (when there were already almost 200 files downloaded). Also the INDEX stages started very late when there were already 300 text items ready to be indexed.
In such processing pipelines performance of single stage is less important than the performance of the whole pipeline. When processing large datasets we want the whole system to be stable in terms of resources usage.
After playing around with different values (and plotting quite some charts) I ended up with the following values:
def perform do
select
|> Flow.from_enumerable(max_demand: 100)
|> Flow.partition(max_demand: 5, stages: 10) # instead of 100 and 50
|> Flow.map(&download/1)
|> Flow.partition(max_demand: 5, stages: 4) # instead of 100 and 50
|> Flow.map(&extract/1)
|> Flow.partition(window: Flow.Window.count(100), stages: 1)
|> Flow.reduce(fn -> [] end, fn item, list -> [item | list] end)
|> Flow.emit(:state)
|> Flow.partition(max_demand: 20, stages: 2) # instead of 100 and 10
|> Flow.map(&index/1)
|> Flow.run
end
This resulted in much better flow of data:
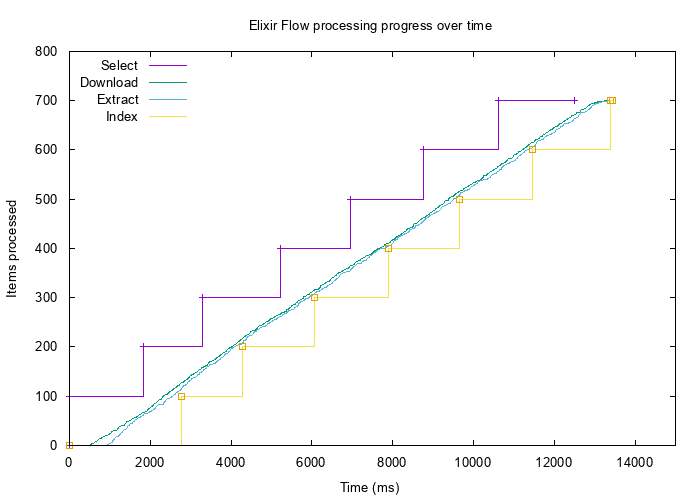
With such tuned parameters all stages are processing data in pipeline minimizing buffering and memory consumption. It also seems to be a little bit faster, but since we are hitting real external services this can’t be taken as a proper speed benchmark.
Few last words
GenStage and it’s higher-level “wrapper” Flow provide building blocks for efficient parallel pipeline processing. Obviously it is not magic and we can’t forget about performance measurements. Yet, I am confident, that when “correct” performance characteristic is achieved the whole system can scale pretty well into larger datasets while keeping the resource usage low.
Looking for comments section?
Send me an email instead to [email protected]